
Event Carried State Transfer: Keep a local cache!
What’s Event Carried State Transfer, and what problem does it solve? Do you have a service that requires data from another service?


What’s Event Carried State Transfer, and what problem does it solve? Do you have a service that requires data from another service? You’re trying to avoid making a blocking synchronous call between services because this introduces temporal coupling and availability concerns? One solution is Event Carried State Transfer.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Temporal Coupling
If you have a service that needs to get data from another service, you might just think to make an RPC call. There can be many reasons for needing data from another service. Most often, it’s for query purposes to generate a ViewModel/UI/Reporting. If you need data to perform a command because you need data for business logic, then check out my post on Data Consistency Between Services.
The issue with making an RPC call and the temporal coupling that comes with it is availability. If we need to make an RPC call from ServiceA to ServiceB, and ServiceB is unavailable, how do we handle that failure, and what do we return to the client?

We want ServiceA to be available even when ServiceB is unavailable. To do this, we need to remove the temporal coupling so we don’t need to make this RPC call.
This means that ServiceA needs all the data to fulfill the request from the client.
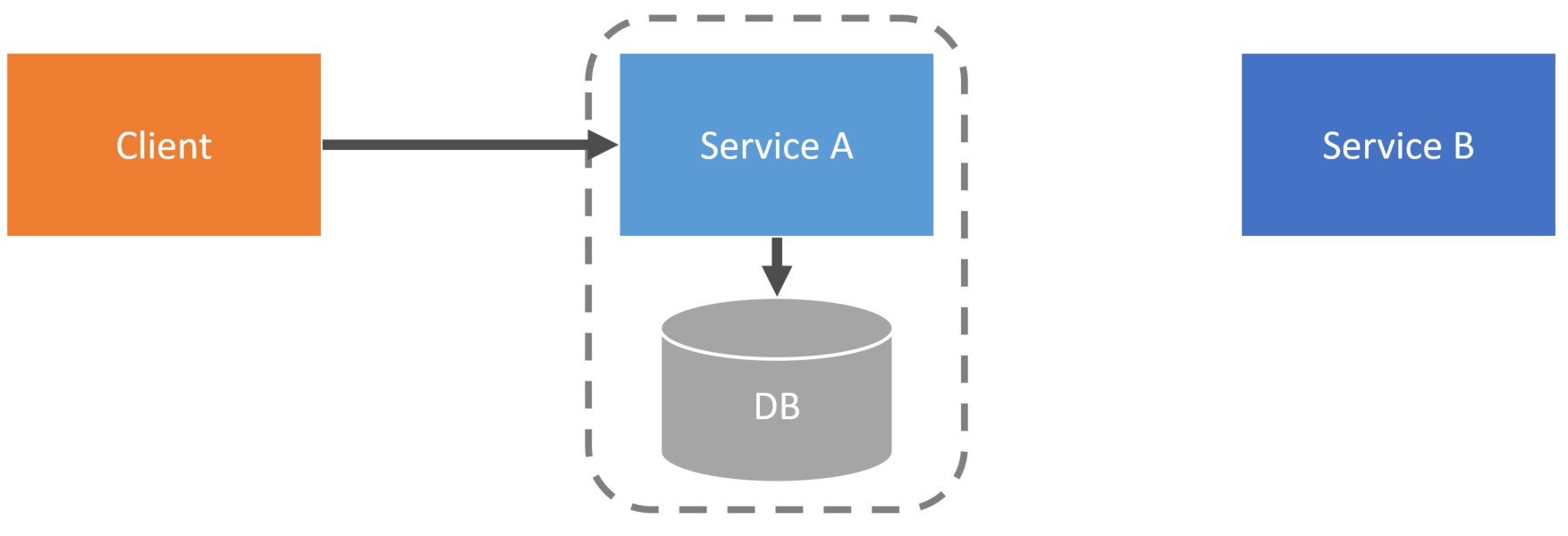
Services should be independent. If a client makes a request to any service, that service should not need to make a call to any other service. It has to have all the data required.
Local Cache
One way to accomplish this is to be notified via an event asynchronously when data changes within a service boundary. This allows you to call back the service to get the latest data/state from the service and then update your database, which is acting as a local cache.
For example, if a Customer were changed in ServiceB, it would publish a CustomerChanged event containing the Customer ID that was changed.
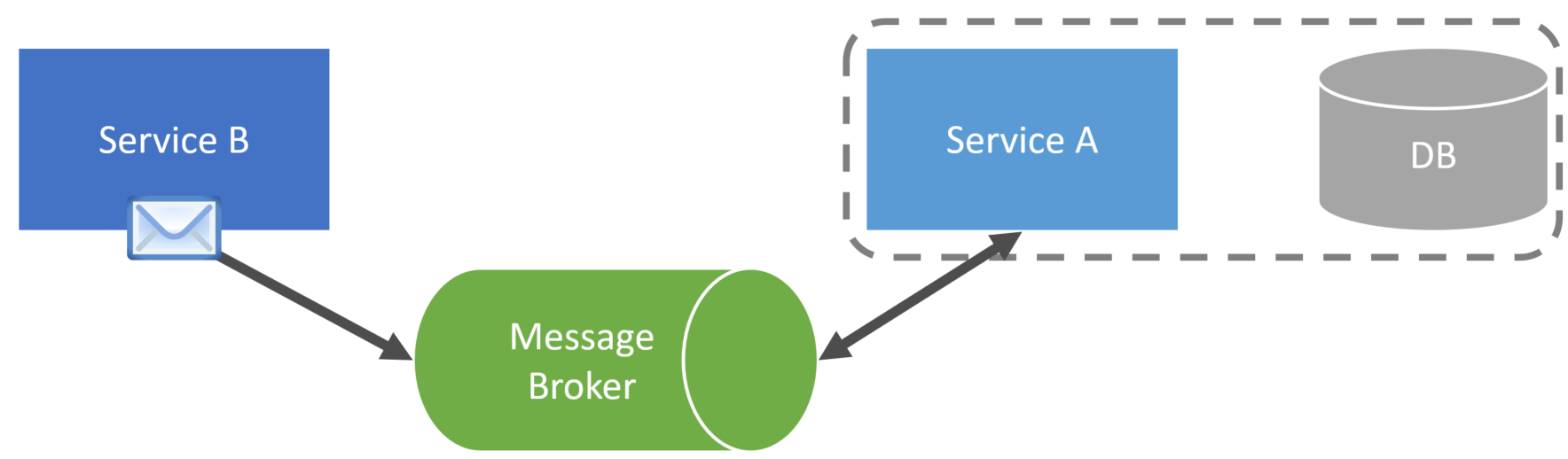
When ServiceA consumes that event, it would then do a callback to ServiceB to get the latest state of the Customer.
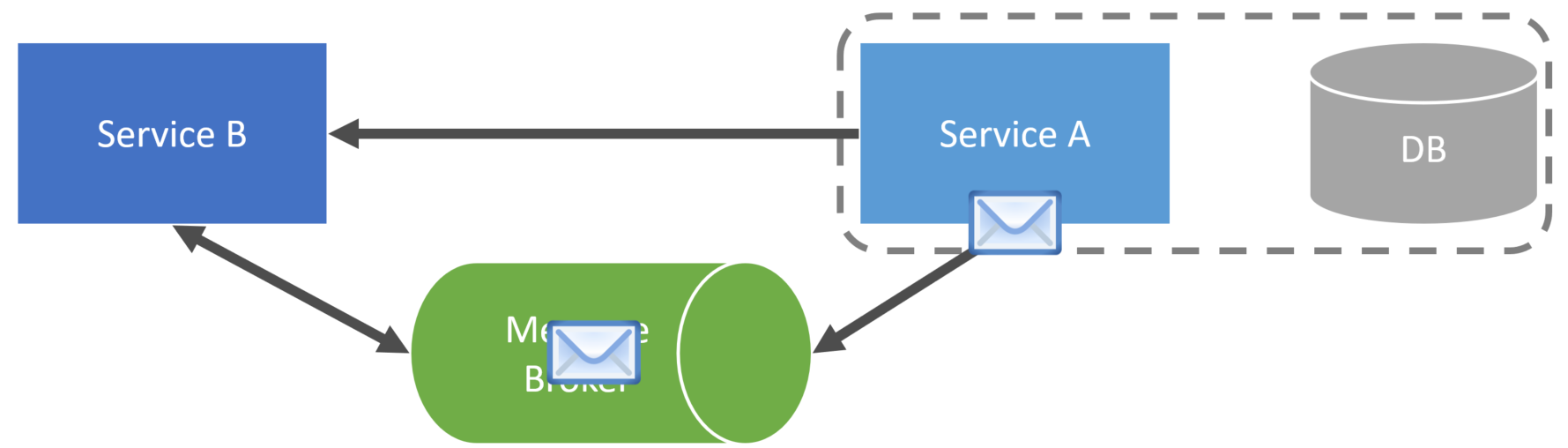
This allows us to keep a local cache of data from other services. We’re leveraging events to notify other service boundaries that the state has changed within a service boundary. Other services can then call the service to update their local cache.
The downside to this approach is that you could be receiving/accepting a lot of requests for data from other services if you’re publishing many events. From the example, ServiceB could have an increased load handling the requests for data.
You’re still dealing with availability, however. If you consume an event and then make an RPC call to get the latest data, the service isn’t available or responding. As with any cache, it’s going to be stale.
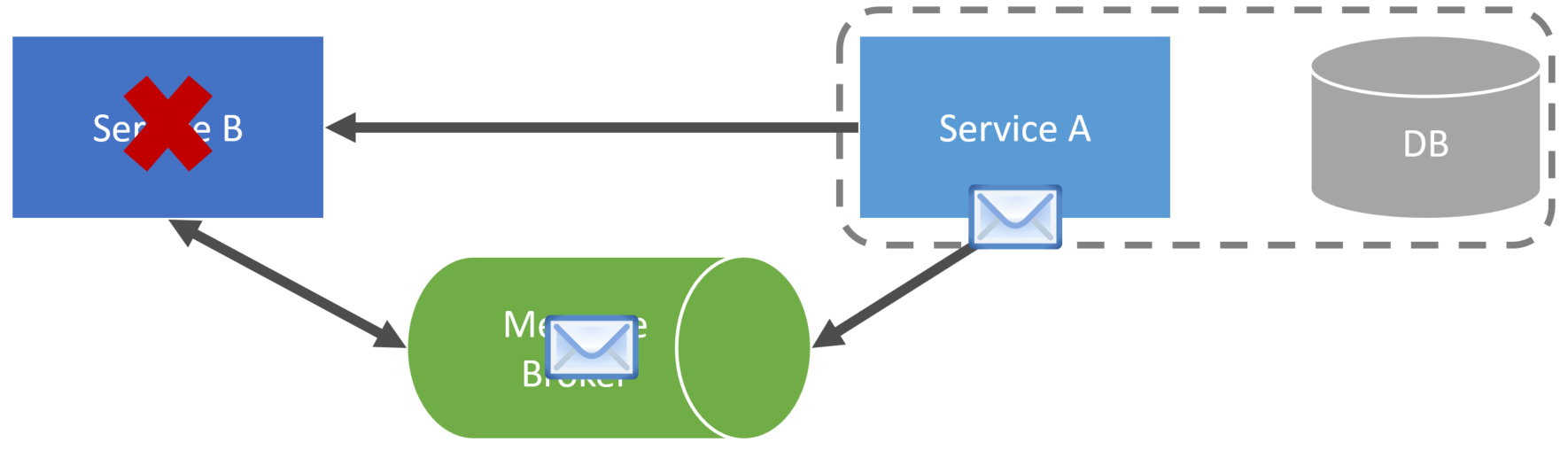
Event Carried State Transfer
Instead of having these callbacks to the event’s producer, the event contains the state. This is called Event Carried State Transfer.
If all the relevant data related to the state change is in the event, then ServiceA can simply use the data in the event to update its local cache.

View the code on Gist.
There are three key aspects to Event Carried State Transfer: Immutable, Stale, and Versioned.
Events are immutable. When they were published, they represented the state at that moment in time. You can think of them as integration events. They are immutable because you don’t own any of the data. Data ownership belongs to the service that’s publishing the event. You just have a local cache. And as mentioned earlier, you need to expect it to be stale because it’s a cache.
Versioning
There must be a version that increments within the event that represents the point in time when the state was changed. For example, if a CustomerChanged event was published for CustomerID 123 multiple times, even if you’re using FIFO (first-in-first-out) queues, that does not mean you’ll process them in order if you’re using the Competing Consumers Pattern.
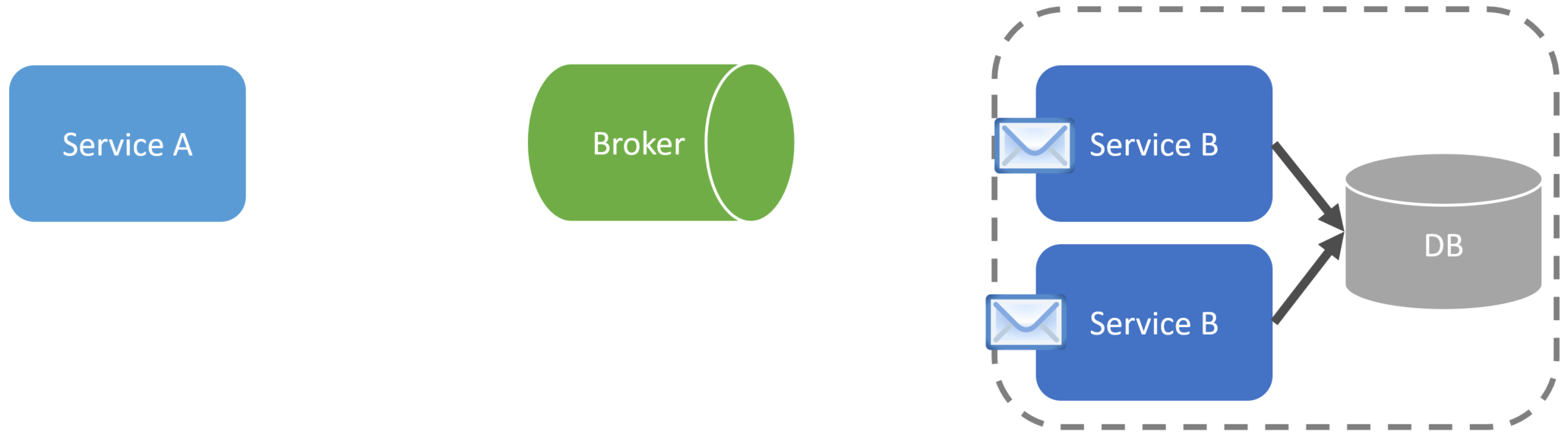
When you consume an event, you need to know that you haven’t processed a more recent version already. You don’t want to overwrite with older data.
Check out my post Message Ordering in Pub/Sub or Queues and Competing Consumers Pattern for Scalability.
Data Ownership
So what type of data would you want to keep as a local cache updated via Event Carried State Transfer? Generally, reference data from supporting boundaries. Not transactional data.
Because reference data is non-volatile, it fits well for a local cache. This type of data isn’t changing often, so you’re not as likely to be concerned with staleness.
Transactional data, however, I do not see as a good fit. Generally, transactional data should be owned and contained within a service boundary.
An example with an online checkout process. When the client starts the checkout process, it makes requests to the Ordering service.
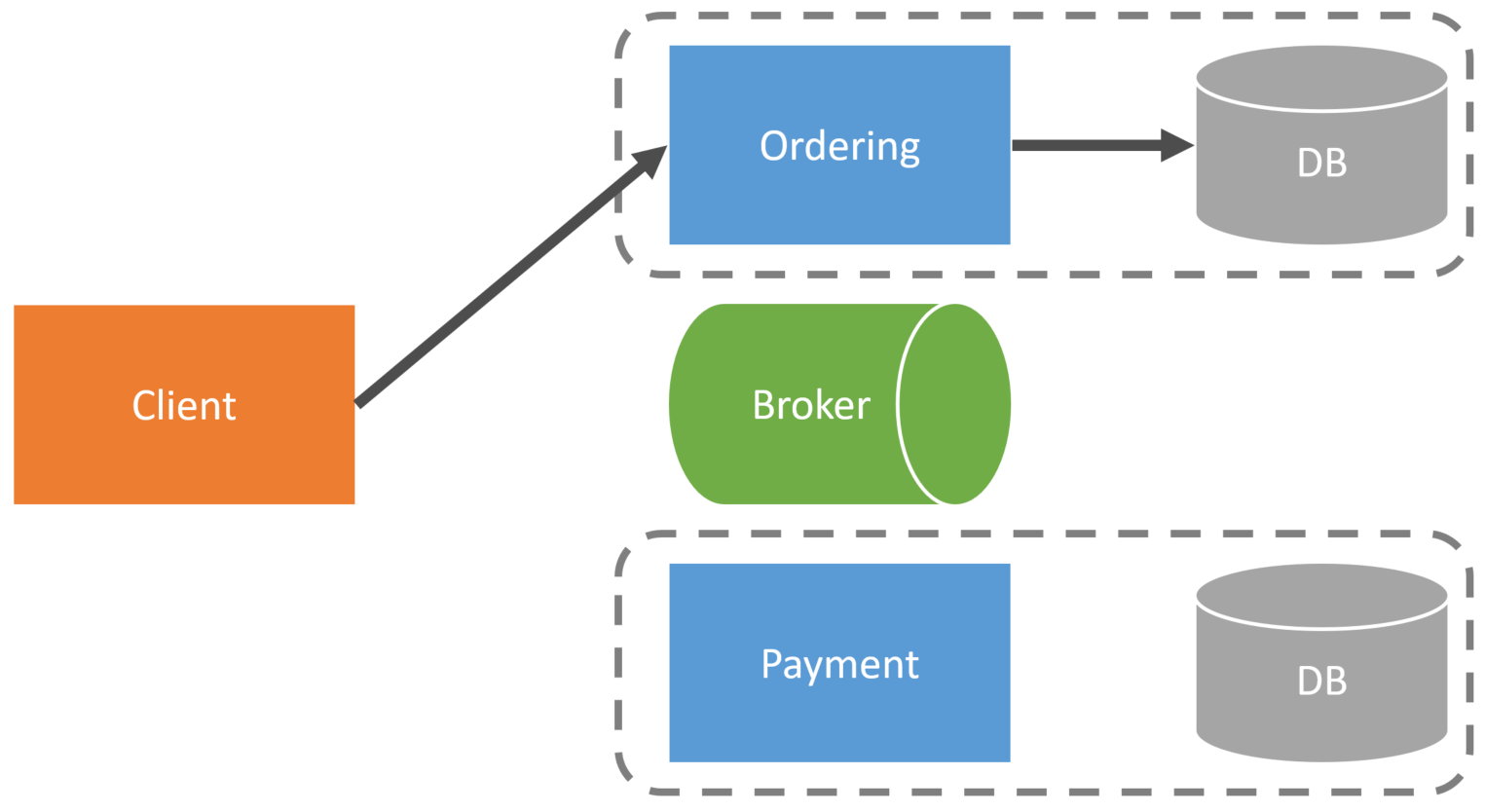
The client then needs to enter their billing and credit card information. This information isn’t sent directly to the Ordering service but to the Payment service. The payment service would store the billing and credit card information to the ShoppingCartID.

Finally, the order is reviewed, and to complete the order, the client then requests the Ordering service to place the order. At this point, the order service would publish an OrderPlaced event only containing the OrderID and ShoppingCartID.
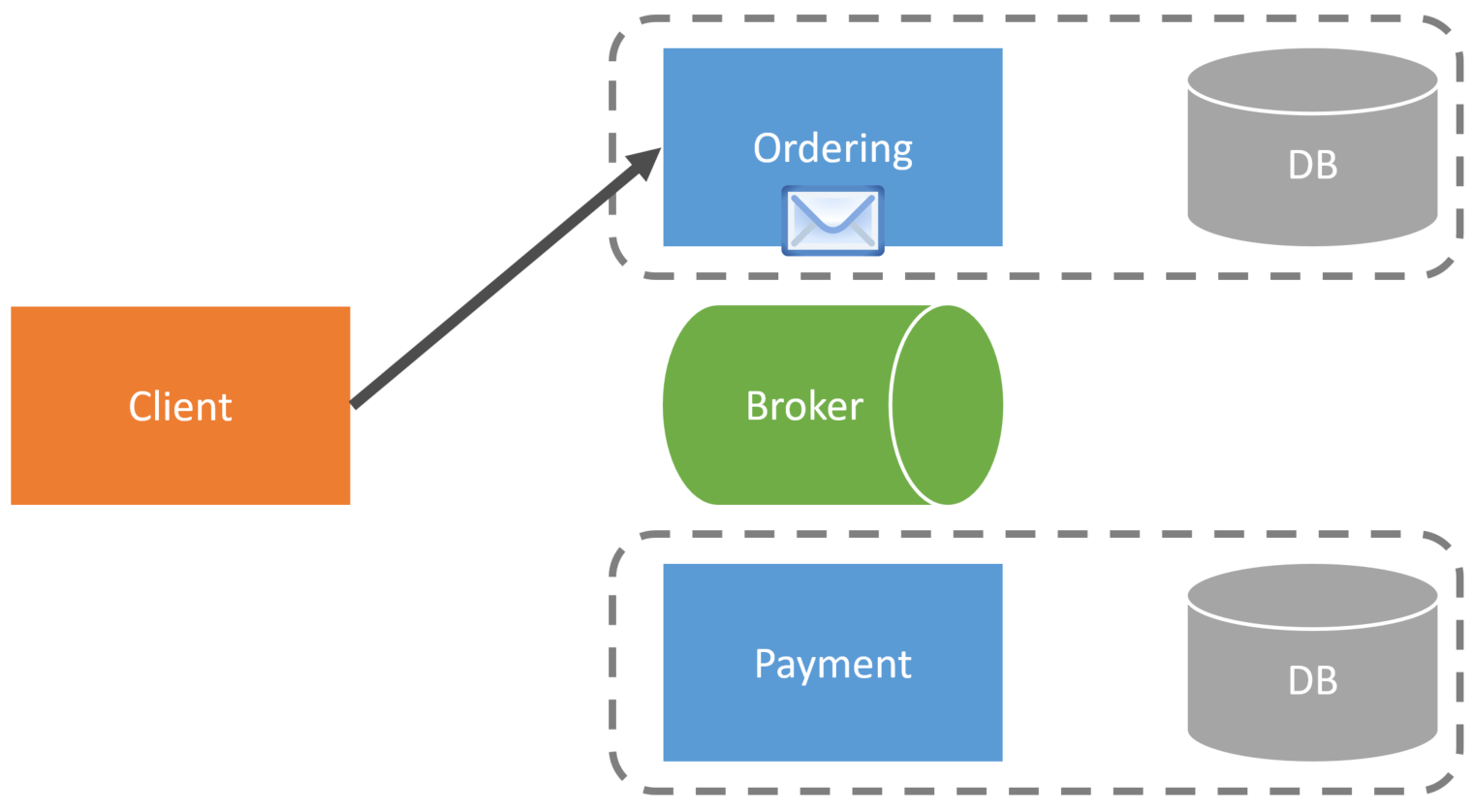
The Payment service would consume the OrderPlaced event and use the ShoppingCartID within the event to look up the credit card information within its database so it can then call the credit card gateway to make the credit card transaction.
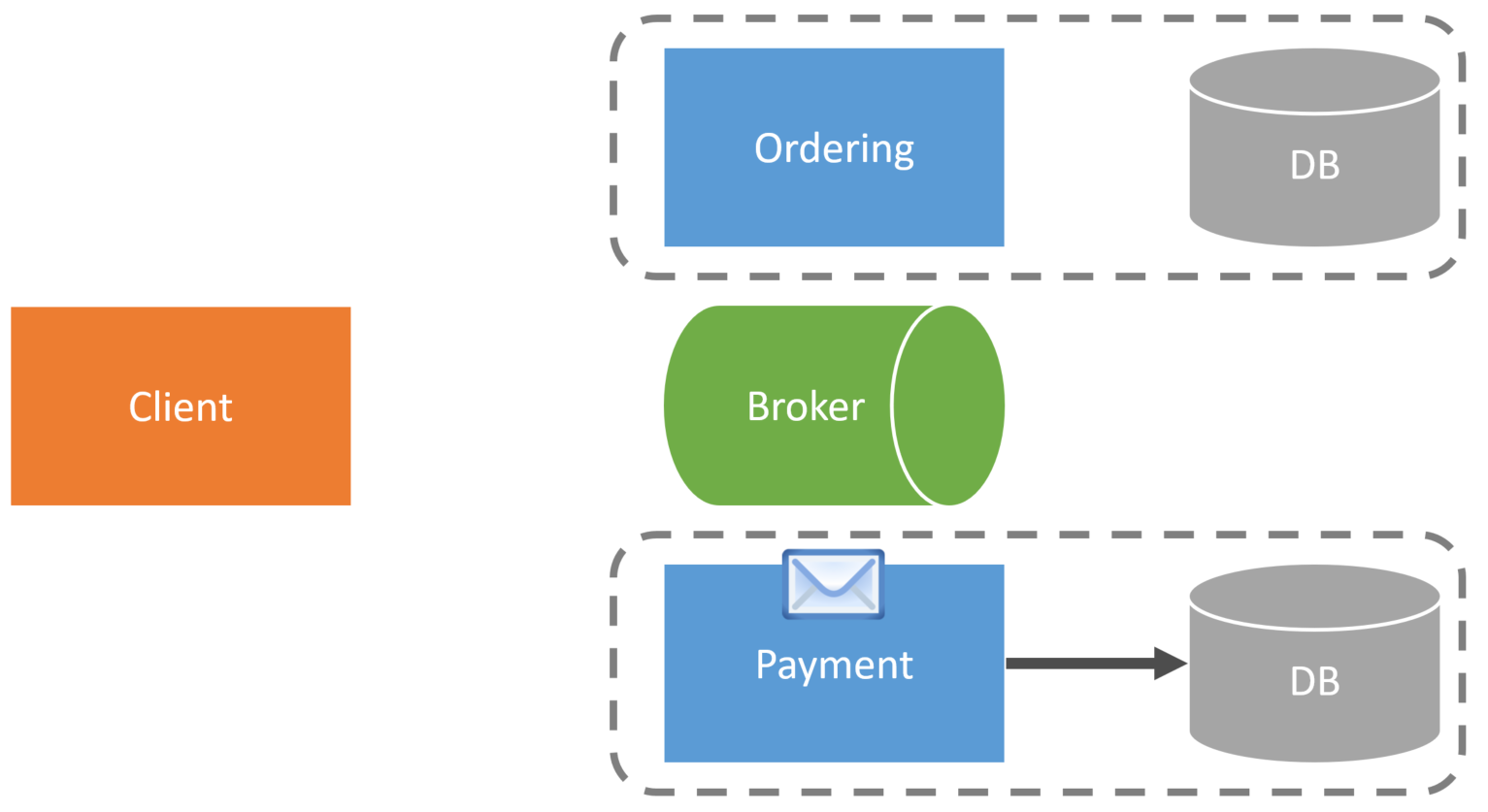
Event Carried State Transfer
Event Carried State Transfer is a way to keep a local cache of data from other service boundaries. This works well for reference data from supporting boundaries that aren’t changing that often. However be careful about using it with transactional data and don’t force the use of event carried state transfer where you should be directing data to the appropriate boundary.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design as well as access to source code for any working demo application that I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.
You also might like
- Data Consistency Between Microservices
- Message Ordering in Pub/Sub or Queues
- Competing Consumers Pattern for Scalability
- Autonomous microservices don’t share data
Follow CodeOpinion
Leave this field empty if you're human:
The post Event Carried State Transfer: Keep a local cache! appeared first on CodeOpinion.